目录
第一部分 概述
在现代软件开发中,插件系统已成为一种常见的架构模式。它允许开发者在不修改核心应用程序的情况下扩展其功能。插件系统是一种设计模式,允许软件应用程序通过插件(扩展模块)来增强其功能。插件通常是独立于主程序的模块,它们通过预定义的接口与主程序进行交互。这种设计的主要优势是高扩展性和灵活性,用户或开发者可以在不改变主程序的情况下添加、更新或删除功能。
1.1 通用实现步骤
- 定义插件接口:创建一个或多个接口,定义插件必须实现的方法。这些接口将作为插件与主程序之间的桥梁。
- 创建插件管理器:实现一个插件管理器类,它负责发现、加载和管理插件。可以使用反射机制或类加载器动态加载插件类。
- 实现插件:创建插件实现类,并实现插件接口。每个插件类应该具备独立的功能,并遵循插件接口的规范。
- 配置插件:使用配置文件或其他方式来描述插件的元数据。这有助于插件管理器识别和加载插件。
- 测试和优化:在实际应用中测试插件系统,确保其稳定性和性能。优化插件的加载和执行过程,以提高系统的效率。
1.2 最佳实践
- 解耦插件和主程序:确保插件与主程序的耦合度尽可能低。使用接口和抽象类来定义插件的功能,避免插件直接依赖于主程序的实现细节。
- 安全性:插件系统可能会引入安全风险,特别是当插件来自不可信的来源时。确保对插件进行适当的验证和沙箱处理,以防止恶意代码的执行。
- 版本管理:管理插件的版本和依赖关系,确保插件在不同版本之间的兼容性。可以使用版本控制和兼容性检查机制来处理插件的更新和升级。
- 性能优化:优化插件的加载和执行过程,确保插件系统的性能不会成为主程序的瓶颈。使用缓存和延迟加载等技术来提高系统效率。
第二部分 SPI
Java中的SPI(Service Provider Interface)是一种在运行时动态发现和加载服务实现的机制。它允许在不修改应用程序代码的情况下,替换或扩展服务实现。SPI广泛应用于各种Java框架和库中,如JDBC、Java Security、Java Persistence API(JPA)等。
2.1 SPI的基本概念
SPI是一种设计模式,用于提供插件式的架构。它包含两部分:
- 服务接口(Service Interface):定义了服务的行为和功能。
- 服务实现(Service Provider):实现服务接口,并提供具体的功能实现。
SPI的核心思想是通过接口和配置文件,将服务的实现与服务的使用解耦,使得在运行时可以灵活地加载不同的实现。
2.2 SPI的使用步骤
假设有一个支付服务,则使用SPI可以分为以下几个步骤:
- 定义服务接口:创建一个服务接口,定义服务提供者需要实现的功能。
javapackage com.jianggujin.spi;
public interface PaymentService {
void processPayment(double amount);
}
- 实现服务接口:创建一个或多个服务提供者类,实现服务接口。
javapackage com.jianggujin.spi;
public class PaypalPaymentService implements PaymentService {
@Override
public void processPayment(double amount) {
System.out.println("Processing payment of $" + amount + " through PayPal.");
}
}
- 配置服务提供者:在
META-INF/services目录下创建一个文件,文件名为服务接口的完全限定名,文件内容是服务提供者实现类的完全限定名。根据上述定义的服务接口与实现,则配置文件路径为:META-INF/services/com.jianggujin.spi.PaymentService,文件中的内容为:com.jianggujin.spi.PaypalPaymentService,需要注意的是配置文件的路径与内容规范是ServiceLoader定义的。 - 加载服务提供者:使用
ServiceLoader类动态加载服务实现。ServiceLoader会根据配置文件找到所有的服务实现,并实例化它们。
javaimport java.util.ServiceLoader;
public class PaymentProcessor {
public static void main(String[] args) {
ServiceLoader<PaymentService> loader = ServiceLoader.load(PaymentService.class);
for (PaymentService service : loader) {
service.processPayment(100.0);
}
}
}
2.3 使用场景
SPI的使用场景非常广泛,以下是一些常见的应用场景:
- 插件架构:在需要支持插件机制的应用程序中,例如某些编辑器或开发环境,可以使用SPI来实现插件的加载和管理。
- 数据库驱动:
JDBC使用SPI机制来加载数据库驱动程序,通过在META-INF/services/java.sql.Driver中配置驱动类,实现了对各种数据库的支持。 - 安全服务:Java安全框架通过
SPI机制加载加密算法、密钥管理器等服务,允许开发者插入自定义的安全服务实现。 - 持久化框架:
JPA利用SPI机制来加载不同的持久化提供者(如Hibernate、EclipseLink),从而支持多种数据库操作实现。
2.4 优缺点
-
优点:
- 灵活性:通过配置文件可以在运行时动态加载和切换服务实现,无需修改代码。
- 扩展性:允许应用程序在运行时扩展功能,支持插件式开发。
- 解耦:将服务的定义与实现分离,使得系统更加模块化。
-
缺点:
- 性能开销:动态加载服务实现可能会带来额外的性能开销。
- 配置管理:需要维护配置文件,管理不同的服务实现。
- 调试复杂性:由于服务的动态加载,可能会增加调试的复杂性。
2.5 SPI与ServiceLoader的关系
-
设计与实现:
SPI是一种设计模式,定义了如何将服务接口和实现解耦。ServiceLoader是实现这一模式的工具,负责动态加载和管理服务实例。 -
配置与加载:
SPI通过配置文件指定服务提供者的实现,而ServiceLoader读取这些配置文件并实例化服务提供者。 -
使用方式:
SPI的设计目标是为了支持服务的动态发现和扩展,ServiceLoader则提供了具体的实现方式,使得服务的加载过程变得简单和透明。
总的来说,SPI是一个高层次的设计概念,描述了服务如何解耦和扩展;而ServiceLoader是 Java 中实现这一概念的实际工具,负责服务的动态加载和管理。除了ServiceLoader的实现方式,在SpringBoot中的自动装配本质上也是SPI的另一种实现,提供了比ServiceLoader更强大的实现加载方式。
第三部分 自定义ClassLoader
使用SPI机制可以满足大部分的场景,一个完善的插件系统会涉及到热加载、类隔离等情况,这个时候使用SPI默认的实现就不太适合了,针对这种场景,通常倾向于自定义ClassLoader的方式进行处理。
3.1 类加载机制
Java虚拟机把描述类的数据从Class文件加载进内存,并对数据进行校验,转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是虚拟机的类加载机制。
虚拟机设计团队把类加载阶段中的“通过一个类的全限定名来获取描述此类的二进制字节流”这个动作放到Java虚拟机外部去实现,以便让应用程序自己决定如何去获取所需要的类。实现这动作的代码模块成为“类加载器”。
类加载过程是将类的字节码加载到内存中,并生成对应的Class对象的过程。类加载过程主要包括以下几个步骤:
- 加载(Loading):类加载的第一个阶段是加载,即将类的字节码文件加载到内存中。加载阶段由类加载器完成,类加载器根据类的全限定名(包括包名和类名)来定位并读取字节码文件。加载阶段的结果是在内存中生成一个代表该类的
Class对象。 - 验证(Verification):在验证阶段,对加载的字节码进行验证,确保字节码的正确性和安全性。验证阶段包括以下几个方面的验证:文件格式验证、元数据验证、字节码验证和符号引用验证。
- 准备(Preparation):在准备阶段,为类的静态变量分配内存并设置默认初始值。这些变量包括静态变量和静态常量。
- 解析(Resolution):在解析阶段,将符号引用解析为直接引用。符号引用是一种符号名称,可以是类、字段、方法等的引用。直接引用是直接指向内存中的地址,可以是指向方法区中的方法、字段等的指针。
- 初始化(Initialization):在初始化阶段,对类进行初始化,包括执行静态变量的赋值和静态代码块的执行。初始化阶段是类加载过程的最后一个阶段,只有在初始化阶段完成后,类才能被正常使用。
需要注意的是,类加载过程是按需加载的,即在首次使用类时才会进行加载。而且类加载过程是线程安全的,即同一个类在多线程环境下只会被加载一次。
另外,类加载过程可以由自定义的类加载器来扩展或修改,默认的类加载器是应用程序类加载器(Application ClassLoader),它负责加载应用程序的类。自定义类加载器可以实现一些特定的需求,如加载加密的字节码文件、从网络或其他非标准位置加载类等。
类与类加载器的关系
类加载器虽然只用于实现类的加载动作,但它在Java程序中起到的作用却远远不限于类加载阶段。对于任意一个类,都需要由加载他的类加载器和这个类本身一同确立其在Java虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类命名空间。通俗来说:比较两个类是否“相等”,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来自同一个Class文件,被同一个虚拟机加载,只要加载他们的类加载器不同,那这个两个类就必定不相等。
3.2 双亲委任模型
3.2.1 双亲委任模型介绍
-
从Java虚拟机的角度:
- 启动类加载器(
Bootstrap ClassLoader):使用C++语言实现(只限HotSpot),是虚拟机自身的一部分 - 其他的类加载器:由Java语言实现,独立于虚拟机外部,并且全都继承自抽象类
java.lang.ClassLoader。
- 启动类加载器(
-
从Java开发人员的角度:将类加载划分的更细致一些,绝大部分Java程序员都会使用以下3种系统提供的类加载器:
- 启动类加载器(Bootstrap ClassLoader): 负责加载存放在
JAVA_HOME/lib目录中的,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如rt.jar,名字不符合的类库即使放在lib目录下也不会重载)类库。 - 扩展类加载器(Extension ClassLoader): 由
sun.misc.Launcher$ExtClassLoader实现,负责加载JAVA_HOME/lib/ext目录下的,或者被java.ext.dirs系统变量所指定的路径中的所有类库。 - 应用程序类加载器(Application ClassLoader): 由
sun.misc.Launcher$AppClassLoader实现。由于这个类加载器是ClassLoader中的getSystemClassLoader方法的返回值,所以也成为系统类加载器。负责加载用户类路径(ClassPath)上所指定的类库。开发者可以直接使用这个类加载器,如果应用中没有定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
- 启动类加载器(Bootstrap ClassLoader): 负责加载存放在
类加载器之间的关系一般如下图所示:
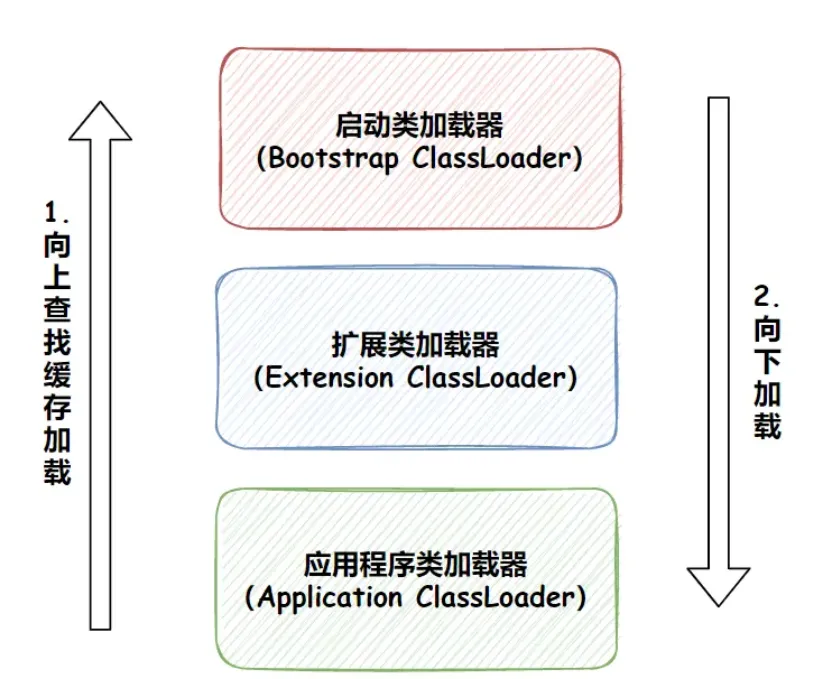
图中各个类加载器之间的关系称为类加载器的双亲委派模型(Parents Dlegation Mode)。双亲委派模型要求除了顶层的启动类加载器之外,其余的类加载器都应当由自己的父加载器优先加载,这里类加载器之间的父子关系一般不会以继承的关系来实现,而是都使用组合关系来复用父加载器的代码。
类加载器的双亲委派模型在JDK1.2期间被引入并被广泛应用于之后的所有Java程序中,但他并不是个强制性的约束模型,而是Java设计者推荐给开发者的一种类加载器实现方式。
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,他首先不会自己去尝试加载这个类,而是把这个请求委派父加载器去完成。每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个请求(他的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
如果没有使用双亲委派模型,由各个类加载器自行加载的话,如果用户自己编写了一个称为java.lang.Object的类,并放在程序的ClassPath中,那系统将会出现多个不同的Object类, Java类型体系中最基础的行为就无法保证,应用程序也将会变的一片混乱。所以,使用双亲委派模型有如下好处:
- 避免类的重复加载: 如果每个类加载器都独立加载类,那么相同的类可能会被多次加载,导致内存中存在多个相同类的副本,这显然是不必要的资源浪费。双亲委派模型确保了类的唯一性,一旦某个类加载器的父加载器已经加载了一个类,子加载器就不会再加载同一个类
- 保证核心类库的一致性: Java的核心类库(如
java.lang.String)位于Bootstrap ClassLoader中。如果允许自底向上的加载方式,用户定义的类加载器可能会尝试加载这些核心类,这可能导致安全问题和版本冲突。双亲委派模型确保了这些基础类只由启动类加载器加载,保证了系统类的统一性和安全性 - 隔离应用程序类和系统类: 不同的应用程序可能定义了相同包和类名的类,但它们应该互不影响。双亲委派模型使得系统类(如
java.*包中的类)与应用程序类(用户自定义的类)得以区分,防止应用程序随意覆盖系统类 - 维护Java的类加载生态: 这种机制使得第三方类库的加载更加有序,开发者可以自定义类加载器来加载特定的类,而不需要担心与系统类发生冲突,因为系统类总是会被先加载
然而,双亲委派机制也有一些缺点:
- 限制了类加载的灵活性:双亲委派机制要求类加载器按照一定的顺序去加载类,这限制了类加载的灵活性。有时候,我们可能需要自定义的类加载器来加载特定的类,但由于双亲委派机制的存在,这些类可能会被父类加载器加载,无法实现自定义加载的需求。
- 难以实现类的动态更新:由于双亲委派机制的存在,当一个类被加载后,它的类定义就不能再被修改。这意味着如果我们想要在运行时动态更新一个类的定义,就需要重新加载整个类及其依赖的类。这对于一些需要频繁更新的应用场景来说,可能会带来一些困扰。
总的来说,双亲委派机制在保证类加载的一致性和安全性方面具有明显的优势,但也存在一定的限制和缺点。在实际应用中,需要根据具体的需求来权衡使用双亲委派机制的利与弊。
3.2.2 打破双亲委派机制
打破双亲委派机制的主要原因是为了满足一些特定的需求和场景,例如:
- 实现类的热部署:在某些应用场景下,需要在运行时动态加载和替换类,以实现热部署的功能。而双亲委派机制会导致类的加载只发生一次,无法实现类的热替换。通过打破双亲委派机制,可以自定义类加载器,在需要时重新加载和替换类。
- 加载非标准的类文件:有些特殊的类文件,如动态生成的字节码、非标准的类文件格式等,无法通过标准的类加载器加载。通过打破双亲委派机制,可以自定义类加载器,实现对这些非标准类文件的加载和解析。
- 实现类加载的动态控制:有些应用需要对类的加载进行特殊的控制,例如对特定的类进行加密、解密或验证等操作。通过打破双亲委派机制,可以自定义类加载器,在加载类时进行特殊的处理。
注意
打破双亲委派机制可能会引入一些潜在的风险和问题,如类的冲突、不一致性等。因此,在打破双亲委派机制时,需要谨慎考虑,并确保自定义的类加载器能够正确处理类的加载和依赖关系。
3.2.3 怎样打破双亲委派机制
在Java中,有以下几种方法可以打破双亲委派机制:
- 自定义类加载器:通过自定义
ClassLoader的子类,重写findClass()方法,实现自定义的类加载逻辑。在自定义类加载器中,可以选择不委派给父类加载器,而是自己去加载类。
javapublic class CustomClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
// 自定义类加载逻辑,例如从特定路径加载类文件
byte[] classBytes = loadClassBytes(name);
return defineClass(name, classBytes, 0, classBytes.length);
}
private byte[] loadClassBytes(String name) {
// 从特定路径加载类文件,并返回字节码
// ...
}
}
- 线程上下文类加载器:通过
Thread类的setContextClassLoader()方法,可以设置线程的上下文类加载器。在某些框架或库中,会使用线程上下文类加载器来加载特定的类,从而打破双亲委派机制。 - OSGi框架:
OSGi(Open Service Gateway Initiative)是一种动态模块化的Java平台,它提供了一套机制来管理和加载模块。在OSGi中,每个模块都有自己的类加载器,可以独立加载和管理类,从而打破双亲委派机制。 SPI机制:SPI(Service Provider Interface)是一种标准的服务发现机制,在SPI中,服务的实现类通过在META-INF/services目录下的配置文件中声明,而不是通过类路径来查找。通过SPI机制,可以实现在不同的类加载器中加载不同的服务实现类,从而打破双亲委派机制。- 使用Java Instrumentation API:Java Instrumentation API允许在类加载过程中修改字节码,从而可以在类加载时修改类的加载行为,包括打破双亲委派机制。通过Instrumentation API,可以在类加载前修改类的字节码,使其加载时使用自定义的类加载器。
- 使用Java动态代理:Java动态代理机制可以在运行时生成代理类,并在代理类中实现特定的逻辑。通过使用动态代理,可以在类加载时动态生成代理类,并在代理类中实现自定义的类加载逻辑,从而打破双亲委派机制。
- 使用字节码操作库:可以使用字节码操作库,如
ASM、Javassist等来直接操作字节码,从而修改类的加载行为。通过这些库,可以在类加载时修改字节码,使其加载时使用自定义的类加载器。
3.3 自定义类加载器
看完前面章节的铺垫,相信各位对类加载器和双亲委派已经有了一定的了解,回到本文的正题,如果我们需要设计一套插件系统,同时需要考虑动态加载、动态卸载、类隔离等情况,则使用自定义类加载器是比较常见的方案。
利用自定义加载器可以将一个或一组类库使用同一个自定义类加载器进行加载,保证在该加载器下的类库进行隔离,若不同的模块需要使用相同的三方包,但是版本不同,则可以针对该种情况使用不同的自定义类加载进行加载即可实现不同版本的类库之间保护不影响,比如在Tomcat中,可以装载多个应用,每个应用可以加载自己需要的三方包而不会相互影响,本质上也是使用了自定义类加载器实现的。
自定义类加载器时本质上是重写loadClass方法,以下是一种实现方式的代码片段。
java@Override
public Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
synchronized (this.getClassLoadingLock(name)) {
if (log.isDebugEnabled()) {
log.debug("load class {}", name);
}
Class<?> clazz;
// 1、检查之前加载的类缓存
if (log.isDebugEnabled()) {
log.debug("try load class from caching");
}
// 1.1 检查自定义的缓存
clazz = this.findLoadedClass(name);
if (clazz != null) {
if (log.isDebugEnabled()) {
log.debug("\t--> returning class from cache");
}
if (resolve) {
this.resolveClass(clazz);
}
return clazz;
}
// 2、尝试使用系统类加载器加载该类,以防止模块重写JavaSE类。这实现了SRV10.7.2
if (this.tryLoadingFromJavaseLoader(name)) {
if (log.isDebugEnabled()) {
log.debug("try load class delegating to javase loader");
}
try {
clazz = this.javaseClassLoader.loadClass(name);
if (clazz != null) {
if (log.isDebugEnabled()) {
log.debug("\t--> returning class from javase loader");
}
if (resolve) {
this.resolveClass(clazz);
}
return clazz;
}
} catch (ClassNotFoundException e) {
// Ignore
}
}
boolean override = this.moduleOverrideStrategy.isEligibleForOverriding(name, true);
// 3、判断是否需要委托给父加载器
if (!override) {
if (log.isDebugEnabled()) {
log.debug("try load class delegating to parent classloader");
}
try {
clazz = Class.forName(name, false, this.parent);
if (log.isDebugEnabled()) {
log.debug("\t--> returning class from parent classloader");
}
if (resolve) {
this.resolveClass(clazz);
}
return clazz;
} catch (ClassNotFoundException e) {
// Ignore
}
}
// 4、尝试自己加载
if (log.isDebugEnabled()) {
log.debug("try load class overriding");
}
try {
clazz = this.findClass(name);
if (clazz != null) {
if (log.isDebugEnabled()) {
log.debug("\t--> returning class from overriding");
}
if (resolve) {
this.resolveClass(clazz);
}
return clazz;
}
} catch (ClassNotFoundException e) {
// Ignore
}
// 5、自己无法加载的时候无条件交给父加载器
if (override) {
if (log.isDebugEnabled()) {
log.debug("try load class delegating to parent classloader");
}
try {
clazz = Class.forName(name, false, this.parent);
if (log.isDebugEnabled()) {
log.debug("\t--> returning class from parent classloader");
}
if (resolve) {
this.resolveClass(clazz);
}
return clazz;
} catch (ClassNotFoundException e) {
// Ignore
}
}
// 6、资源未找到
if (log.isDebugEnabled()) {
log.debug("\t--> class not found, returning null");
}
}
throw new ClassNotFoundException(name);
}
上述代码片段中提供了一种实现的思路,实际应用中除了加载类文件之外,还会涉及资源的查找、卸载时的资源销毁等,如需了解更多的实现,可以参考Tomcat中的自定义加载器WebappClassLoaderBase实现。
3.4 加载插件
使用自定义类加载器定义插件的步骤与SPI机制大体上是一致的,都需要定义接口与实现,主要差异在于如何加载插件。可以通过如下几种方法实现:
- ClassLoader#loadClass():在已知实现的全限定类名后,可以使用自定义类加载器实例的
Class<?> loadClass(String name)方法进行加载 - Class.forName():
Class<?> forName(String name, boolean initialize, ClassLoader loader)可用于使用指定的类加载器加载指定全限定类名的实现,同时initialize参数可以指定在加载完成后是否初始化该类 - ServiceLoader.load():区别于
SPI章节中查找的用法,此处可以使用<S> ServiceLoader<S> load(Class<S> service, ClassLoader loader)方法进行加载
提示
在使用自定义类加载器实现插件系统时,通常接口应该使用应用类加载器进行加载,实现类由不同的自定义类加载进行加载,避免在主程序中无法使用接口引用到具体的实现实例。
第四部分 PF4J实现插件
4.1 PF4J介绍
PF4J(Plugin Framework for Java)是一个为Java应用程序提供插件框架的工具。它允许开发者通过插件系统将功能模块化,提高应用程序的扩展性和灵活性。PF4J提供了一个简单易用的API,用于管理插件的生命周期、加载插件以及提供插件间的依赖管理功能。
使用场景
- 模块化应用程序:当你希望将应用程序的不同功能拆分成多个模块,并且希望这些模块能独立开发、测试和部署时。
- 可扩展性:在需要为现有应用程序添加新的功能或集成第三方模块时,PF4J 可以帮助你实现功能的动态加载。
- 插件化架构:当你的应用程序需要提供插件机制,让用户可以根据需求自定义功能时,PF4J 提供了完美的解决方案。
优点
- 易于集成:PF4J 提供了简单的 API 和配置方式,能够轻松地与现有应用程序集成。
- 灵活性:支持插件的动态加载和卸载,插件可以在运行时更新或修改,增强了系统的灵活性。
- 依赖管理:允许插件之间相互依赖,并能处理插件依赖问题,使得复杂的插件结构变得容易管理。
- 扩展性:支持插件的自动发现和加载,支持自定义插件加载器,能够处理各种需求的插件系统。
缺点
- 性能开销:由于插件的动态加载和卸载可能带来一定的性能开销,特别是在插件数量较多时。
- 复杂性:插件系统的设计和管理可能会增加系统的复杂性,需要仔细规划和设计插件的结构和接口。
- 安全性:使用插件机制时需要注意安全性问题,确保插件的安全性和可信度,防止潜在的安全风险。
4.2 快速集成示例
下面是一个基本的PF4J集成示例,展示如何在Java应用程序中集成和使用PF4J框架。
- 添加依赖
首先,在pom.xml中添加
PF4J的Maven依赖:
xml<dependencies>
<dependency>
<groupId>org.pf4j</groupId>
<artifactId>pf4j</artifactId>
<version>3.12.0</version>
</dependency>
</dependencies>
- 创建插件接口
定义一个插件接口,这个接口将被所有插件实现:
javapublic interface Plugin {
void execute();
}
- 实现插件
创建一个插件实现类,并将其放置在插件目录中:
javapublic class PluginImpl implements Plugin {
@Override
public void execute() {
System.out.println("MyPluginImpl executed!");
}
}
将这个实现打包成JAR文件,放在插件目录下,例如plugins目录。
- 配置
PF4J
创建一个主程序,配置PF4J并加载插件:
javaimport org.pf4j.DefaultPluginManager;
import org.pf4j.PluginManager;
import org.pf4j.PluginWrapper;
public class Main {
public static void main(String[] args) {
// System.getProperty("pf4j.pluginsDir", "plugins")
PluginManager pluginManager = new DefaultPluginManager();
pluginManager.loadPlugins();
pluginManager.startPlugins();
// 获取插件实例并调用其方法
for (PluginWrapper wrapper : pluginManager.getStartedPlugins()) {
Plugin plugin = (Plugin) pluginManager.getExtensionFactory().create(wrapper.getPluginId(), Plugin.class);
plugin.execute();
}
}
}
- 运行程序
确保插件
JAR文件在指定的插件目录下,运行主程序,就可以看到插件的输出信息。
4.3 总结
PF4J是一个功能强大的插件框架,适用于需要动态加载和管理插件的Java应用程序。通过PF4J,开发者可以轻松实现应用程序的模块化和扩展功能。尽管PF4J具有一定的复杂性和性能开销,但其灵活性和扩展性使其成为构建插件化架构的有力工具。
更多使用方式可参考PF4J官网:https://pf4j.org/
提示
除了本文介绍的几种实现以外,还可以使用Java中的脚本引擎实现插件系统,关于Java脚本引擎的用法可以参考另一篇博文《Java脚本引擎与动态编译》


本文作者:蒋固金
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!